Stage 2018
Introduction
Du 02 Juillet 2018 au 30 Juillet 2018, j’ai effectué un stage au sein du département informatique de l’IMT Atlantique. Au cours de ce stage, j’ai pu m’intéresser aux différents algorithmes d’estimation du squelette humain.
Dans le cadre de l’utilisation du robot Poppy pour exécuter des exercices de kinésithérapie, ce robot utilise une caméra Kinect afin de détecter le squelette du patient et évaluer l’exécution du mouvement. Mon travail au cours de ce stage a été d’évaluer d’autres algorithmes permettant la détection du squelette humain et leur comparaison avec la Kinect et la Xsens.
J'ai travaillé avec les modules suivants :
- Tensorflow
- Caffe : Framework Deep Learning (Travaille sous Cuda ou CPU_Only)
- pycaffe : module python de Cafffe (Nécessite que caffe soit installé)
- OpenCV2 ou OpenCV3.
Installations
- Installation de Caffe
Caffe est un framework écrit en C++ avec une interface python sous le nom de pycaffe. L'installation du framework est détaillée dans le lien suivant : https://chunml.github.io/ChunML.github.io/project/Installing-Caffe-Ubuntu/
Il faudra configurer ensuite le path de Caffe comme suivant :
Path caffe à rajouter dans le bashrc (vim ~/.bashrc), à adapter selon l’endroit où se situe caffe:
export PYTHONPATH=/home/y17bendo/caffe/python:$PYTHONPATH
Pour les utilisateurs de Caffe en GPU, rajouter les paths suivants :
export LD_LIBRARY_PATH=“$LD_LIBRARY_PATH:/usr/local/cuda/lib64”
export CUDA_HOME=/usr/local/cuda
Installer également skimage si le module n'est pas installé (sudo apt-get install python3-skimage).
- Installation de OpenCV3 pour ubuntu 18.04 :
Toutes les instructions sont disponibles sur le lien suivant :
https://www.pyimagesearch.com/2018/05/28/ubuntu-18-04-how-to-install-opencv/
Implémentations
- Caffe :
Cette implémentation utilise des Parts Affinity Fields pour détecter les différentes parties du corps de différentes personnes dans une image. Le modèle a été pré-entraîné avec COCO et utilise 6 stages.
Ce code reçoit les paramètres suivants:
-L’image.
-Le scale : C’est la taille à laquelle l’image est redimensionnée avant d’être traitée par le réseau de Neurones.
Le code principale permettant de traiter une seule image est le fichier : processing_image.py présent sur le serveur Greiner dans le répertoire suivant : Realtime_Multi-Person_Pose_Estimation/testing/python
- Tensorflow :
Une seconde implémentation du Deep Pose Estimation basé sur Tensorflow. Cette implémentation fournit plusieurs variantes en modifiant la structure de neurones ce qui permet de choisir entre vitesse de traitement et précision de l’estimation.
La version Mobilenet_thin étant la plus légère et la version cmu étant la plus lourde. L’implémentation est disponible sur Greiner dans le répertoie tf-openpose.
Comparaison des implémentations
Plusieurs tests ont été exécutés afin de comparer le temps de traitement des différentes implémentations et leurs différentes variantes. Le tableau suivant illustre le temps de calcul pour chacun des tests:
| Scale | Stage | CPU/GPU | Temps Scaling (ms) |
|---|---|---|---|
| 0.25 | 6 | CPU | 1576.30 |
| 0.5 | 6 | CPU | 6009.74 |
| 1.25 | 6 | CPU | 42585.52 |
| 1.5 | 6 | CPU | Failure |
| 2 | 6 | CPU (Greiner) | 107388 |
| 0.5 | 6 | GPU | 149.73 |
| 0.75 | 6 | GPU | 348.13 |
| 1 | 6 | GPU | 453.33 |
| 1.25 | 6 | GPU | Failure |
-Les tests en CPU ont été faits sur la vm (4 coeurs) sauf pour le test CPU (Greiner) qui a été exécuté sur la machine Greiner en mode CPU (32 coeurs).
-Les tests en GPU ont été faits sur Greiner également.
Plus le scaling est grand plus le temps de traitement l’est. Cependant, au delà d’un seuil la vm plante pour une raison d'insuffisance de RAM (scale de 1,5 pour la vm), et le programme plante sur Greiner au dela d’un scale de 1,25 en mode GPU en raison d’une insuffisance de mémoire sur la carte graphique (11GB).
Le mode GPU est nettement plus rapide.
Le tableau suivant illustre la différence en temps en modifiant les stages dans l’implémentation sous Caffe. Le temps de traitement est proportionnel au nombre de stages diminue considérablement d’un rapport de 2/3 . Ceci s’explique par le fait que le temps de passage par chaque stage est identique. Néanmoins la précision de l’estimation se dégrade également en diminuant le nombre de stages.
| Scale | Stage | Temps Scaling (ms) | Rapport |
|---|---|---|---|
| 0.25 | 6 | 1576.3 | 1.566 |
| 0.25 | 4 | 1006.05 | |
| 0.5 | 6 | 6009.74 | 1.433 |
| 0.5 | 4 | 4191.68 |
Un dernier test a été fait sur des vidéos et en calculant le frames per second (fps) pour chaque implémentation.
| Tensorflow Implementation | Caffe Implementation | |||||
|---|---|---|---|---|---|---|
| Mobilenet Model | CMU Model | Greiner GPU Scale 0.5 | Greiner GPU Scale 1 | vm scale 0.25 | vm scale 0.5 | |
| Fps | 5 fps | 0.42 fps | 0.45 fps | 0.32 fps | 0.4 fps | 0.14 fps |
La mobilenet_thin est la plus rapide (5 fps), tandis que les implémentations sous Caffe sont plus lents. En terme de précision, la cmu est comparable à un scale de 0,5 sous Caffe.
Dès lors, pour les tests suivants, nous avions décidé de comparer de manière quantitative la mobilenet avec les données fournies par le Kinect et la Xsens.
Code Principale (Choix de l’algorithme)
Le programme principal suivant (./Algo/run_algo.py ) permet de traiter une vidéo et estimer les positions des membres du corps de personnes apparaissantes dans une vidéo, plusieurs modes et choix sont possibles comme suivant:
| Argument | Type | Default | Description |
|---|---|---|---|
| video | String | “” | Path of the video to use |
| modèle | String | “mobilenet_thin” | Model to use : mobilenet_thin,cmu,caffe |
| scale | Float | 0.5 | scale for caffe model |
| save | String | “” | path where to save the processed frames |
| nb_images | int | 140 | Echantillonnage de la vidéo |
| live | bool | False | |
| save_video | String | “” | Repertoire où enregistrer la vidéo |
| save_data | String | “” | Repertoire où enregistrer les données de la Mobilenet |
| screen | bool | False | Afficher la vidéo traitée au cours du traitement |
Procédure
Afin de comparer les données de la Kinect, de la Mobilenet et de la Xsens. Ces données doivent subir plusieurs modifications selon la procédure suivante :
- Coloriage de la vidéo en supprimant le squelette.
- Collecte des données de la Mobilenet.
- Conversion des données de la Xsens en format de données Kinect.
- Superposition des squelettes.
- Interpolation des données.
- Comparaison effective des différentes données.
Cela est possible en utilisant les scripts suivants:
Coloriage de la vidéo en supprimant le squelette:
Les données brutes fournies contiennent le squelette de la Kinect tracé sur la vidéo. Il faut tout d’abord corriger cela en supprimant le squelette et en essayant de recolorier la vidéo.
Pour cela, le programme (Algo/Scripts/Remove_Skeleton.py) permet de détecter les pixels rouges du squelette, les supprime et les remplace en faisant une moyenne sur un carré de 16 pixels centré sur le pixel que l’on souhaite supprimer sans prendre en compte les pixels rouges.
Ce programme parcourt la vidéo frame par frame et enregistre le résultat sous forme d’une nouvelle vidéo avec la possibilité d’enregistrer les frames.
Une fois la vidéo coloriée, nous disposons d’une vidéo relativement similaire à l'originale avec quelques défauts notamment au niveau des extrémités des membres et à certains endroits où le squelette est de couleur presque orange similaire à celle des capteurs. En diminuant encore plus le seuil de (R,G,B) les capteurs étaient aussi coloriés.
\\Le squelette coloriée, nous pouvons à présent collecter les données de la Mobilenet.
Collecte des données de la Mobilenet
Cette étape permet de collecter les données de la mobilenet sous forme de json au même format que ceux de la Kinect, avec la seule différence que les données collectées sont en X,Y au lieu de Z,X,Y.
Pour cela, on utilise le code principale en choisissant comme algorithme la mobilenet avec l’option save_data et en précisant comme vidéo d’entrée la vidéo coloriée.
Le format de la Kinect étant le suivant : {“positions”: {
frame : {
BodyPart :
[ Z, X, Y ] } } }
Etant donné que les parties du corps détectés par la Kinect et la Mobilenet ne sont pas les mêmes, nous nous sommes contentés de collecter uniquement les parties du corps communes afin de pouvoir les comparer.
Conversion des données de la Xsens en format de données Kinect:
Afin de pouvoir uniformiser les données, le programme (Conversion_Xsens_json_format.py) reçoit les données de la Xsens en fichier xmlx et les convertit au même format que ceux de la Kinect.
Conversion des données Skeleton2D de la Kinect :
Certaines données de la Kinect étaient en format différent (cf figure ci-dessous). Un autre programme (Conversion_Skeleton_Kinect.py) permet de les convertir au format standard de la Kinect.

A ce stade, toutes les données de la Kinect, Mobilenet et Xsens sont au même format souhaité.
Superposition des squelettes:
Avant d’entamer la comparaison, il faut tout d’abord superposer les différentes données. Pour cela, les deux programmes (Supperposition_Mobilenet_Kinect.py et SupperpositionXsens_Kinect.py) automatisent la superposition, et un autre programme (python3 plot_skeletons.py in folder Algo/Scripts) permet de visualiser les squelettes superposés. La superposition se fait par rapport aux données de la Kinect de la manière suivante :
- Rotation selon l’axe des y pour les données de la Xsens.
- Rescale du squelette en se basant sur la longueur des jambres (genou à la cheville)
- Superposition des middle Shoulders en exécutant une translation dans le plan (X,Y)
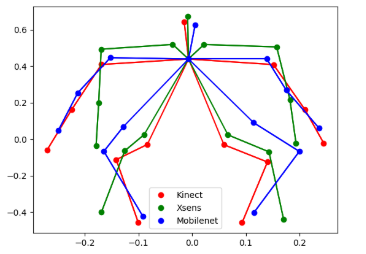
A ce stade, les données sont superposées spatialement. La prochaine étape consiste à les superposer temporellement.
Interpolation des données:
Afin de pouvoir comparer les données à chaque instant, le programme (Interpolation.py) permet, selon la caméra à l’entrée, d’interpoler les données. Afin de ne pas être dans un cas d’extrapolation, il est recommandé d’exécuter l’interpolation dans un intervalle de temps inférieure à l’intervalle de temps initial.

Maintenant que les données sont tous superposées spatialement et temporellement, nous pouvons enfin passer à une comparaison quantitative.
Comparaison des données:
Cette étape consiste consiste à tirer des résultats comparatifs des différentes caméras, en se basant sur la Xsens comme vérité terrain. Avant d’analyser les résultats, il est nécessaire de mentionner que les squelettes sont superposés spatialement uniquement au niveau du middle Shoulder, des différences entre les squelettes existent en raison de la position des capteurs de la Xsens qui est différente des parties du corps détectées par la Kinect. De même, les parties du corps détectées par la Kinect ne sont pas forcément identiques à celles de la Mobilenet. C’est pour cela que nous nous intéresserons notamment à l’évolution de ces différences et l’évolution de leur écart-type.
Pour cela, on utilise les deux programmes suivants :
- Le premier consiste à comparer les 3 méthodes: Kinect, Mobilenet et Xsens. (comparaison_Kinect_Mobilenet_Xsens.py)
- Le deuxième consiste à comparer la Kinect et la Mobilenet en utilisant les données du Skeleton2D converties au bon format. (comparaison_Kinect_Mobilenet.py)
Les deux programmes permettent de comparer l’évolution des positions X,Y , de l’écart-type et de la distance entre les différentes méthodes et ce pour chaque partie du corps.
La comparaison des parties gauches du squelette donnent des résultats cohérents et interprétables.
 Pour un profil de face, la Kinect détecte toujours toutes les différentes parties du corps. Or, ce n’est pas le cas pour la Mobilenet. Par ailleurs, pour un profil de côté, la Mobilenet est plus précise que la Kinect.
Pour un profil de face, la Kinect détecte toujours toutes les différentes parties du corps. Or, ce n’est pas le cas pour la Mobilenet. Par ailleurs, pour un profil de côté, la Mobilenet est plus précise que la Kinect.


Cependant, après quelques tests, il s’est avéré que des complications persistent au niveau de la variance et de l’écart type de la partie droite du corps. Au début, j'ai soulevé un problème d'effet miroir. En effet, la gauche et la droite de la Kinect sont inversés par rapport à ceux de la Kinect et la Xsens. Une fois ce problème résolu, un autre problème persistait au niveau de la variance et l'écart-type de la partie droite. En effet, les valeurs d'écart-type (en mètre) sont relativement grand, tandis que la vérité terrain montre que la différence n'est pas autant grande.
Les résultats suivants sont ceux de la vidéo Chris1 pour la poignée Droite.

Conclusion
Pour conclure, ce projet a permi l’implémentation de différentes versions de l’algorithme OpenPose tel quel la Mobilenet sous Tensorflow et l’implémentation sous Caffe.
Après comparaison de ces implémentations avec la Mobilenet et la vérité terrain représentée par la Xsens. Il paraît que l’implémentation sous Caffe est la plus performante pour un scale au dessus de 1. Toutefois, cette version est très lente et ne peut pas être utilisée pour un rendu en temps réel. D’autre part, la mobilenet est la version la plus rapide d’OpenPose. Ses résultats sont comparables à ceux de la Kinect.
Malheureusement, faute de temps je n’ai pu exécuter plus de comparaisons afin de mieux interpréter les résultats de ces comparaisons. Toutefois, les programmes que j’ai pu écrire permettront à d’autres personnes d'exécuter d’autres comparaisons et d’utiliser la Mobilenet et l’implémentation sous Caffe.
Compléments
- Le squelette utilisé dans tf_pose_estimation est le modèle COCO. La correspondance des index et des parties du corps est consultable sur https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/master/doc/output.md#keypoint-ordering et https://github.com/ildoonet/tf-pose-estimation/blob/460dfab9a73784455c314c7a979dd87a36b35f4f/tf_pose/common.py